DiDi – Differential Directory Indexing Method
The Differential Directory (DiDi) stores only the difference between each key and the previous one (already sorted), instead of storing full keys in each node.
DiDi is a versatile and efficient indexing method applicable to files, directories, keys,
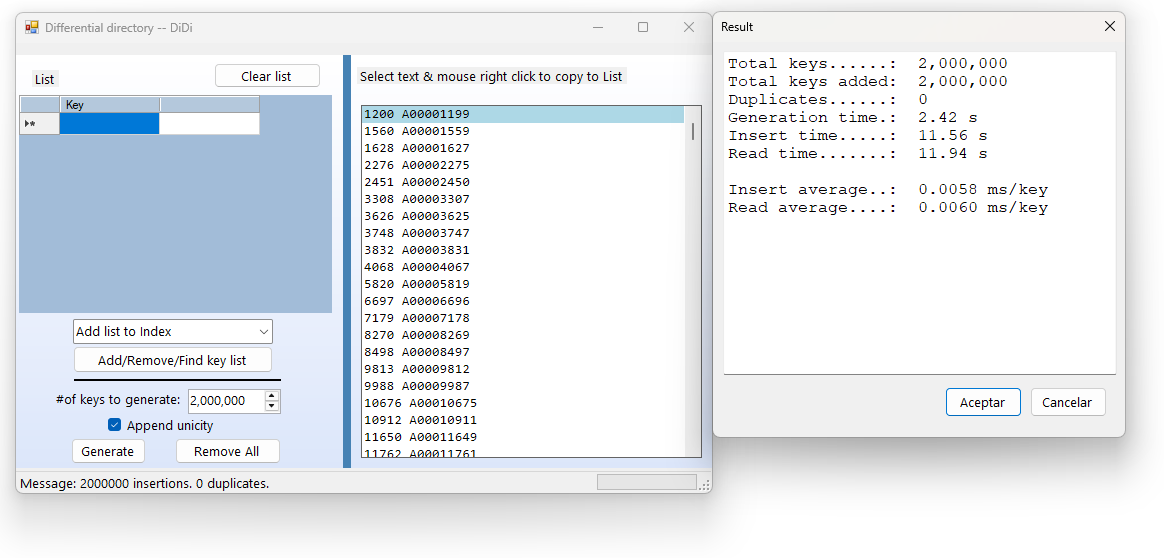
and similar structures. Performance benchmarks demonstrate that inserting 2 million keys
requires just 6.9 microseconds per key (total time: 13.81 seconds), while a complete read
of all keys takes 7 microseconds per key (total time: 13.96 seconds) on a system powered
by a 12th Gen Intel® Core™ i5-12400 @ 2.50 GHz running Windows 11.
Features
- Retrieves the differentiating bit of a key with respect to the previous one and stores only this position in the index.
- With at most one single disk read, assuming the index is in memory, it determines whether the key exists or not.
- The index is always sorted and therefore requires no reorganization.
- Performance is proportional to the length of the keys, not to the size of the index.
- Insertions require updating at most two or three nodes.
Differential Directory (DiDi) – Brief Description
The Differential Directory (DiDi) stores only the difference between each key and the previous one (already sorted), instead of storing full keys in each node.
Much like when writing a list by hand and using quotation marks (“) to indicate repetition from the line above —for example:
John Miles
“ Smith
DiDi applies a similar concept, but instead of letters, it identifies the first differing bit between keys.
It stores this bit position in a node, which also holds references to its left and right children (if present), as well as to the disk record where the complete key and associated data are stored.
For instance, if the first key inserted is "John Smith", the index is initially empty. The first differing character (compared to “nothing”) is J at position 1, so the index becomes 1J → record 1.
If we then insert "John Miles", we read 1J, confirm it matches at position 1, and read record 1. The index is updated to:
1J → record 1, right → record 2, and then 6S → record 2.
Now, if we insert "John Serrote", we find that position 6 in record 1 is not S, so we follow the pointer to record 2. If it matches, we insert a new node 6e between records 1 and 2, updating the structure to:
1J → record 1, right → record 3,
6S → record 3, right → record 2,
and finally
7m → record 2 (with no children).
With this structure —which is a bit more elaborate— the index remains sorted, and only a maximum of 3 nodes and a single disk read (maximum) are required per insertion.
Download
The Differential Directory (DiDi) is available from the Downloads page.
A video demonstration of DiDi
GitHub
You can view the complete DiDi project, including source code and README, on
GitHub.